D-FINE is a cutting-edge algorithm developed to overcome the limitations of existing Transformer-based object detection models (DETR series), particularly in bounding box regression and slow convergence. This article focuses on D-FINE’s core mechanisms—Fine-grained Distribution Refinement (FDR) and Global Optimal Localization Self-Distillation (GO-LSD)—and provides a detailed analysis of its architecture, technical contributions, performance benchmarks, and a comparison with YOLOv12.

1. Background and Motivation
DETR (Detection Transformer) was revolutionary for eliminating anchors and non-maximum suppression (NMS) from object detection pipelines. However, it introduced several challenges in real-world applications:
- Extremely slow convergence
- Inefficient direct regression of bounding box coordinates
- Limited real-time applicability without high-end hardware
D-FINE retains the Transformer backbone but enhances the bounding box prediction process for faster and more precise localization.
2. Key Technique ① Fine-grained Distribution Refinement (FDR)

Traditional DETR models predict bounding boxes directly as a single vector. However, this method struggles to localize objects accurately when they are ambiguous or visually similar to the background.
To overcome this, D-FINE introduces the FDR mechanism, which models each bounding box coordinate as a Gaussian distribution and refines these distributions iteratively through multiple layers.
Specifically, each of the coordinates (x1, y1, x2, y2) is represented using Gaussian-based modeling and progressively updated via refinement layers. This approach offers several advantages:
- Explicit quantification of spatial uncertainty
- Robust predictions even in cluttered or ambiguous scenes
- Improved approximation precision for bounding box coordinates
3. Key Technique ② Global Optimal Localization Self-Distillation (GO-LSD)
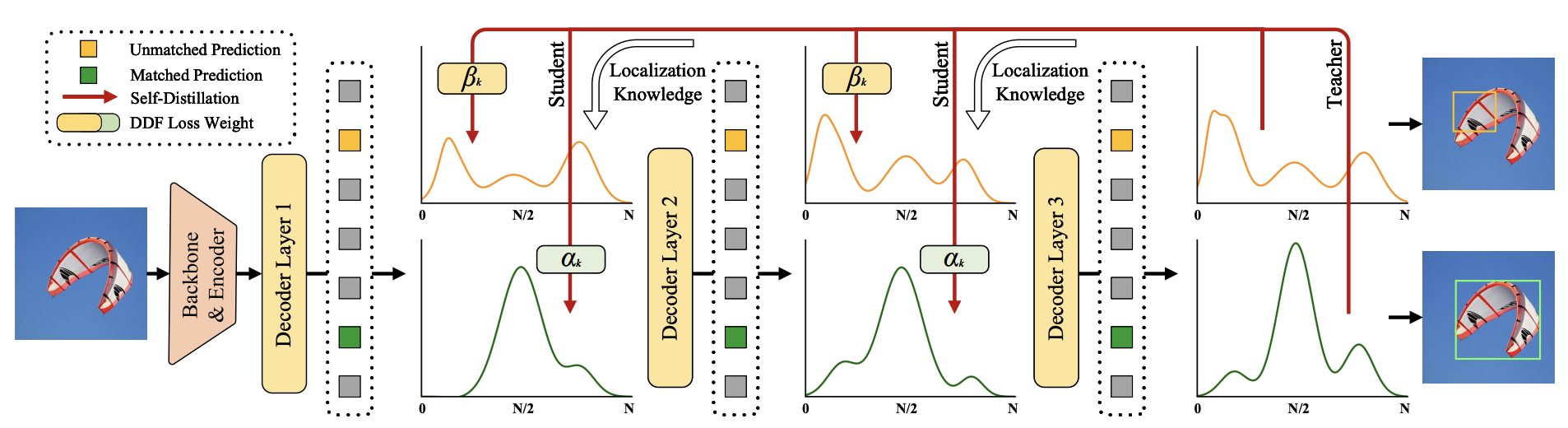
This structure transmits high-quality localization information obtained from deep layers to the shallow layers, guiding the overall network's learning. It is a type of self-distillation technique with the following goals:
- Applying the final bounding box predicted by deep layers to the shallow decoder
- Mitigating cumulative errors during multi-stage box refinement
- Improving overall learning stability and accuracy
GO-LSD uses distribution-based predictions as soft targets and trains the shallow decoder's predictions using soft loss. As a result, the model improves overall learning efficiency and converges in fewer epochs.
4. Performance Results (COCO Benchmark)
- D-FINE-L: AP 54.0%, 124 FPS @ NVIDIA T4
- D-FINE-X: AP 55.8%, 78 FPS @ NVIDIA T4
- D-FINE-L (Objects365 pretrain): AP 57.1%
- D-FINE-X (Objects365 pretrain): AP 59.3%
When compared to DETR variant models under the same conditions, D-FINE achieves an average 2–4% higher AP, and it is capable of real-time processing in terms of speed.
5. Comparative Analysis with YOLOv12
YOLOv12 is based on a lightweight CNN architecture optimized for real-time inference, whereas D-FINE is a transformer-based detection model. The key differences include:
- Architecture: D-FINE uses a Transformer (DETR-like) backbone, while YOLOv12 uses a CNN-based Backbone + Neck + Head structure.
- Localization: D-FINE applies distribution-based coordinate refinement (FDR), while YOLOv12 uses direct regression.
- Inference Speed: D-FINE reaches 78–124 FPS on GPU, whereas YOLOv12 (e.g., YOLOv12-N) can go up to 600 FPS.
- Accuracy (AP): D-FINE achieves up to 59.3%, while YOLOv12-S reaches around 46.5%.
- Use Case: D-FINE is suited for high-precision detection in medium-to-large models; YOLOv12 targets lightweight real-time applications.
6.FRD Sample Code
# Pseudo-code for FDR Head
def fdr_head(input_feature):
distribution = predict_distribution(input_feature)
refined = iterative_refinement(distribution)
return box_from_distribution(refined)
7. Conclusion
D-FINE enhances the accuracy of object detection while addressing limitations found in DETR. Its combination of distribution-based regression and self-distillation strategy represents a key technical contribution. Unlike real-time CNN-based models such as YOLOv12, D-FINE targets scenarios requiring high-precision real-time object detection, making it a strong candidate for accuracy-critical applications.
Comments
Post a Comment